Conclusion
Now that we have created our snake with the Q-Learning algorithm, we can start to test the snake and generate our results. In order to keep everything simple, I decided to run 100 replications and trials ranging from 10 to 200 increasing the number of trials by 10 each time.
If we do that, we will get the following data:
[
{
"trials": 10,
"replications": 50,
"final_scores": "1 3 8 2 3 4 2 0 3 4 1 2 4 2 2 4 1 4 6 2 4 2 1 1 6 3 2 4 6 3 1 2 4 3 4 2 1 2 3 3 3 1 3 2 0 4 2 2 6 3"
},
{
"trials": 20,
"replications": 50,
"final_scores": "2 5 3 5 4 1 3 6 10 1 2 3 1 3 2 8 5 2 7 7 6 7 0 6 2 5 2 3 10 7 1 3 7 10 3 6 5 6 6 2 5 2 4 5 2 4 1 2 4 3"
},
{
"trials": 30,
"replications": 50,
"final_scores": "3 14 7 4 11 7 9 8 2 4 6 17 4 7 3 5 7 7 5 4 3 5 7 3 8 7 5 6 15 6 5 1 6 8 4 4 1 17 3 6 6 1 8 2 1 7 14 5 9 3"
},
{
"trials": 40,
"replications": 50,
"final_scores": "2 10 4 3 6 2 7 9 4 11 4 2 2 10 3 4 4 1 5 0 12 3 5 1 10 6 11 11 7 5 8 4 1 10 5 10 3 9 4 6 6 5 6 2 4 5 2 16 18 2"
},
{
"trials": 50,
"replications": 50,
"final_scores": "7 6 5 5 14 14 10 11 6 3 9 19 1 11 12 15 5 4 13 4 6 2 8 4 6 10 14 5 8 7 11 14 6 2 5 13 0 4 2 8 10 0 1 5 11 7 6 7 9 9"
},
{
"trials": 60,
"replications": 50,
"final_scores": "6 6 6 20 5 15 8 5 2 5 8 7 9 16 17 7 8 17 12 1 6 15 1 2 13 4 4 6 6 9 11 3 2 6 11 14 10 7 9 10 6 12 8 6 14 18 4 13 16 9"
},
{
"trials": 70,
"replications": 50,
"final_scores": "2 3 5 16 13 7 7 5 9 8 9 6 7 10 2 10 12 2 12 9 1 7 4 16 9 9 7 10 9 18 5 3 8 12 3 10 4 10 12 8 16 22 1 11 1 1 9 7 8 1"
},
{
"trials": 80,
"replications": 50,
"final_scores": "9 8 5 9 7 4 8 11 25 19 10 9 11 6 10 9 13 1 8 5 15 14 14 8 9 13 16 9 13 18 1 15 9 12 2 12 10 12 12 8 13 13 1 15 4 11 12 3 5 7"
},
{
"trials": 90,
"replications": 50,
"final_scores": "3 3 10 21 1 17 9 13 1 1 9 4 8 12 7 25 15 13 22 15 17 8 2 12 6 15 8 11 9 11 28 6 14 9 8 10 9 14 5 1 14 16 5 27 16 6 7 7 19 12"
},
{
"trials": 100,
"replications": 50,
"final_scores": "1 14 12 6 14 7 9 14 11 5 5 6 14 17 18 5 21 10 10 8 8 11 9 11 16 11 5 15 12 7 9 14 10 25 3 5 9 11 6 11 11 10 1 11 6 14 19 21 7 16"
}
] From this, extracting the values from the JSON format and computing a 95% confidence interval will give a graph such as the following.
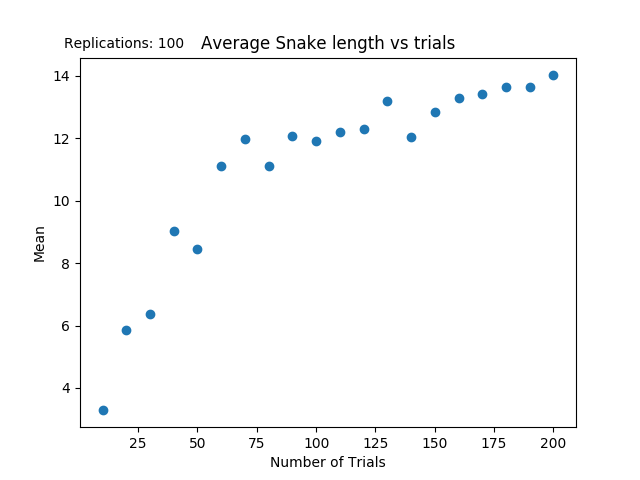
This graph looks logarithmic, but we need to check if that is statistically significant. In order to perform this, we can do a linear regression. The problem is that we don’t have linear data.
Since we can hypothesize that our data is logarithmic, if we exponentiate every piece of data (take each piece of data, x, and make it x^e) then we will have linearized data (if it truly is logarithmic).
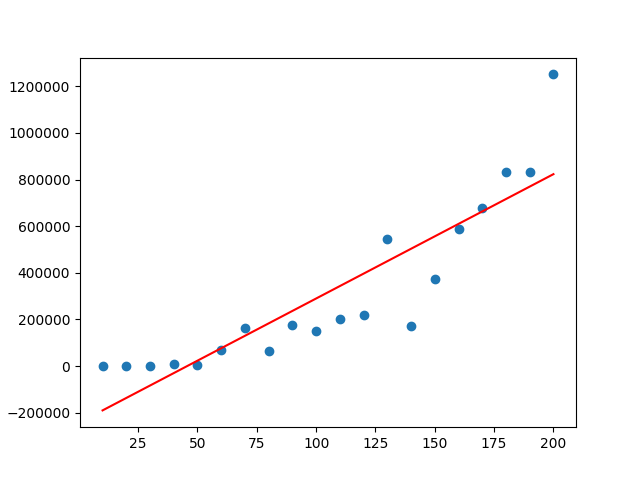
Then, from our linear data, we can perform a linear regression on the data to find a line of best fit. Once we have our line of best fit, we can conver the data to logarithmic data by taking the natural log (ln) of each piece of data on the regression line.
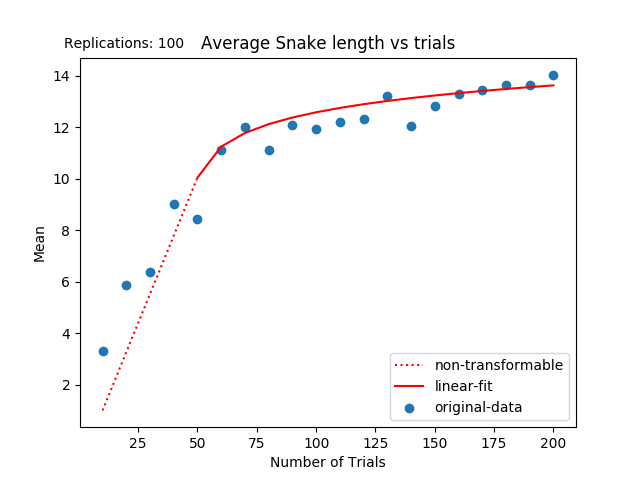
As we can tell, this line is a very good fit of the data. This is further shown by the R^2 value of the original data and the line of regression is .77, which shows a statistically significant correlation that the data is logarithmic.
Well what does this mean? This means that, while Q-Learning can be very effective at the beginning, it quickly levels off and the effects are drastically reduced. However, if it truly is a logarthmic cuvre, that means it is montonically increasing, meaning that it will never stop increasing.
Overall, for the first level of complexity, the snake performed well and was able to get a respectable score. Now we just have to create the next level of complexity ot see how this graph changes.